
Microsoft provides a good documentation on how to ingest monitoring data over event-hubs and preparing it for Azure Data Explorer, Tutorial: Ingest and query monitoring data in Azure Data Explorer. The solution provided by Microsoft collects all Diagnostic data in a central table, which is counterproductive if alerts or detailed queries are needed. So how can one create more detailed tables?
Sending of data
Azure resources provide diagnostic data that match their purpose. This data is then sent to event-hub topic as a JSON message, which can contain either 1 record or multiple records depending on how the data is sent.
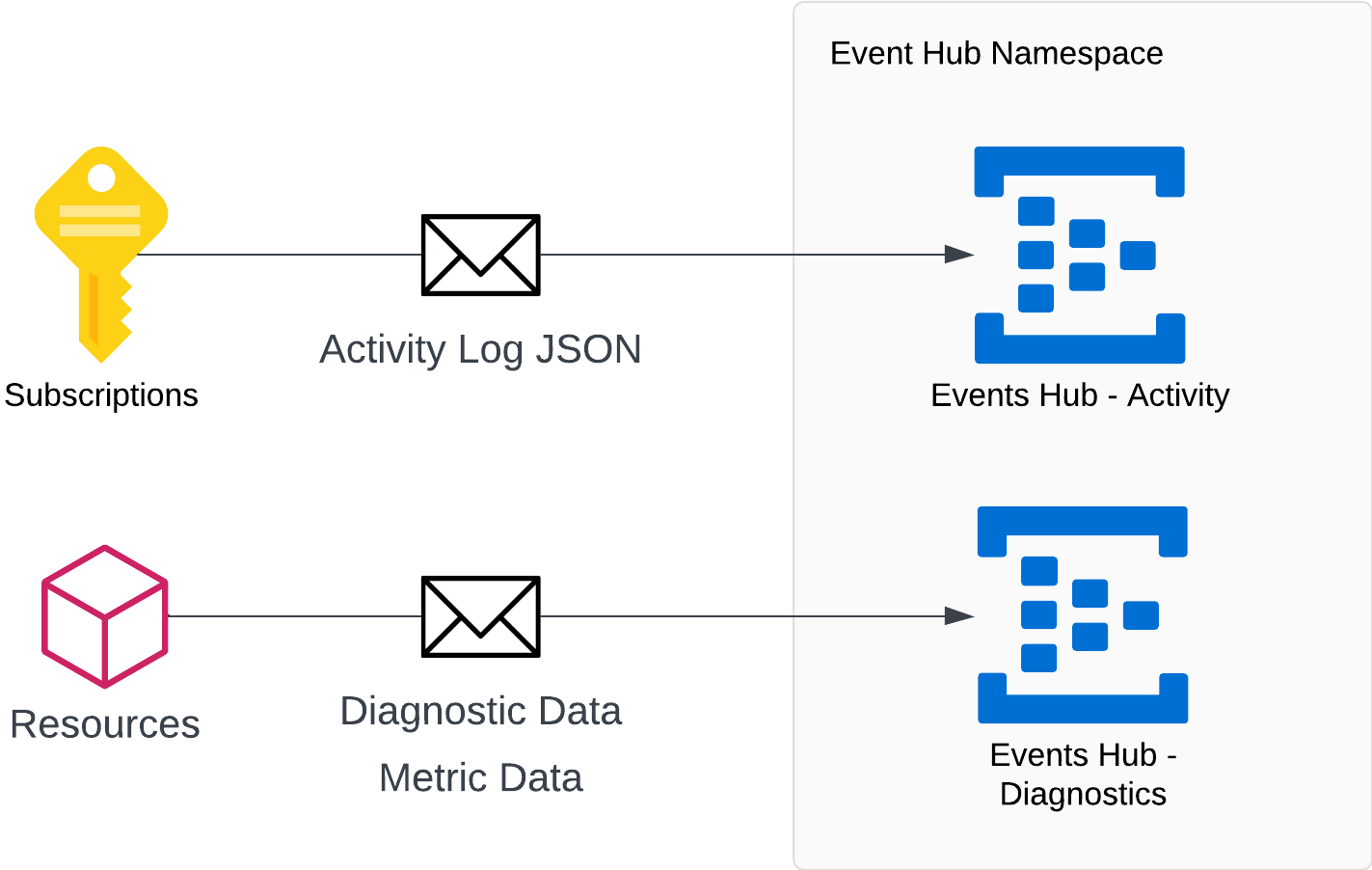
As recommended by Microsoft tutorial, having 2 event hubs is enough to support the data sent by all resources. The activity logs are quite straightforward, and they are collected at subscription level. On the other hand, the Diagnostic Logs are sent different per resource type. This is due to the information that each service needs to report.
Processing of events
Azure Data Explorer provides Data Connectors which connect with data providers and import the data available. Importing the diagnostic data requires an event hub data connector to be created. The data connector takes the event hub connection details. The most important part of the setup is to assign the Target Table. This requires the table where the message is imported with a mapping. While the mapping can be created to parse the JSON received, and this ideal when the event hub data matches the target table columns, in case of diagnostic data the records are mapped to one field that will hold the event JSON data.
Processing of Diagnostic Data
This is where the fun part starts. Once the data is stored in the diagnostic raw logs, it needs to be processed and imported into the relevant table. If you follow the tutorial by Microsoft, https://learn.microsoft.com/en-us/azure/data-explorer/ingest-data-no-code, and try to check the contents of DiagnosticRawRecords you will see that there is no data. This is due to the retention policy that is set on the table, which is to remove the data immediately.
.alter-merge table DiagnosticRawRecords policy retention softdelete = 0d
To understanding the message structure that is sent by a resource, it is suggested to set the softdelete value to at least 1hour. This will provide enough time to query the DiagnosticRawRecords table to get some sample messages for the resource being analysed.
.alter-merge table DiagnosticRawRecords policy retention softdelete = 1h
The DiagnosticRawRecords table will start accumulating quite some records. Furthermore, a resource might send more than 1 type of message which might have different set of fields. Therefore, it is best to query for the resource either using the Resource ID or by using the ARM resource type in the resource ID field. Note that the latter is not as reliable as using the Resource ID either as a direct match or with contains.
Example: Determining the distinct categories of API Management and finding samples of one of the categories
- Checking the distinct categories of data send using operation name field
DiagnosticRawRecords | mv-expand events = Records | where events.operationName contains "Microsoft.ApiManagement" | summarize count() by tostring(events.category)
- Getting some message samples
DiagnosticRawRecords | mv-expand events = Records | where events.category == "GatewayLogs" | project events | limit 10
Given some sample data is available, the detailed Diagnostic data for a resource type can be constructed. To construct a table in Kusto, the following syntax can be used.
.create table <Table Name> ( <field name>: <field type>. <field name>: <field type>. ...... )
Continuing the above example, a GatwayLog message will look like:
"events": {
"category": "GatewayLogs",
"operationName": "Microsoft.ApiManagement/GatewayLogs",
"properties": {
"method": "POST",
"url": "https://myapim.azure-api.net/url-path",
"backendResponseCode": 200,
"responseCode": 200,
"responseSize": 2454,
"cache": "none",
"backendTime": 2769,
"requestSize": 2807,
"apiId": "********",
"operationId": "*********",
"apimSubscriptionId": "master",
"clientTime": 11,
"clientProtocol": "HTTP/1.1",
"backendProtocol": "HTTP/1.1",
"apiRevision": "1",
"isTraceAllowed": true,
"isMasterTrace": true,
"clientTlsVersion": "1.2",
"backendMethod": "POST",
"backendUrl": "http://10..../url-path"
},
"resourceId": "/SUBSCRIPTIONS/*****/RESOURCEGROUPS/SOME_RG/PROVIDERS/MICROSOFT.APIMANAGEMENT/SERVICE/MY_APIM",
"time": "2023-11-06T12:40:58.8117273Z",
"DeploymentVersion": "0.40.16708.0",
"Level": 4,
"isRequestSuccess": true,
"durationMs": 2782,
"callerIpAddress": "*****",
"correlationId": "6d153214-0227-490a-8a81-709015c0478f",
"location": "West Europe",
"resultType": "Succeeded",
"truncated": 0
}Basing on this information, the table for API Management Gateway Logs can be defined as:
.create table APIManagementDiagnosticLogs ( Timestamp: datetime, Category: string, ResourceId: string, OperationName: string, Method: string, Url: string, BackendResponseCode: int, ResponseCode: int, ResponseSize: int, Cache: string, BackendTime: long, RequestSize: long, ApiId: string, OperationId: string, ClientProtocol: string, BackendProtocol: string, BackendId: string, ApiRevision: string, ClientTlsVersion: string, BackendMethod: string, BackendUrl: string, DeploymentVersion: string, Level: int, IsRequestSuccess: bool, DurationMs: long, CallerIpAddress: string, CorrelationId: string, Location: string, Result: string, Truncated: long )
Once the resource table is defined, the next step is to define a function that will import and convert the diagnostics raw data to the resource table. The function query will look like this
.create-or-alter function APIMDiagnosticLogsExpand() {
DiagnosticRawRecords
| mv-expand events = Records
| where isnotempty(events.operationName) and events.operationName startswith "Microsoft.ApiManagement/GatewayLogs"
| project
Timestamp = todatetime(events['time']),
Category = tostring(events.category),
ResourceId = tostring(events.resourceId),
OperationName = tostring(events.operationName),
Method = tostring(events.properties.method),
Url = tostring(events.properties.url),
BackendResponseCode = toint(events.properties.backendResponseCode),
ResponseCode = toint(events.properties.responseCode),
ResponseSize = toint(events.proeprties.responseSize),
Cache = tostring(events.properties.cache),
BackendTime = tolong(events.properties.backendTime),
RequestSize = tolong(events.properties.requestSize),
ApiId = tostring(events.properties.apiId),
OperationId = tostring(events.properties.operationId),
ClientProtocol = tostring(events.properties.clientProtocol),
BackendProtocol = tostring(events.properties.backendProtocol),
BackendId = tostring(events.properties.backendId),
ApiRevision = tostring(events.properties.apiRevision),
ClientTlsVersion = tostring(events.properties.clientTlsVersion),
BackendMethod = tostring(events.properties.backendMethod),
BackendUrl = tostring(events.properties.backendUrl),
DeploymentVersion = tostring(events.DeploymentVersion),
Level = toint(events.Level),
IsRequestSuccess = tobool(events.isRequestSuccess),
DurationMs = tolong(events.durationMs),
CallerIpAddress = tostring(events.callerIpAddress),
CorrelationId = tostring(events.correlationId),
Location = tostring(events.location),
Result = tostring(events.resultType),
Truncated = tolong(events.truncated)
}Here some explanations and caveats need to be highlighted. The first item that pops-up is there is no Insert statement. The reason for no Insert statement, is that this is a transformation function, and we will need to do a policy update on the target table for the inserts to occur. In this case on APIManagementDiagnosticLogs. The command to perform the policy update is
.alter table APIManagementDiagnosticLogs policy update @'[{"Source": "DiagnosticRawRecords", "Query": "APIMDiagnosticLogsExpand()", "IsEnabled": "True", "IsTransactional": true}]'The second point to be highlighted is the sequence of the fields in the transformation function. While in SQL and NoSQL world, people are accustomed to column matching, this is not the case for Kusto transformation function. The sequence in the function need to match the sequence in the target table. Furthermore, another caveat is that the function cannot provide extra or less columns than the target table(s). Otherwise, the policy update will return a schema mismatch.
Another caveat to be aware is that the data need to be expanded to use it in the query. While the UI displays the raw data as JSON, this is not how the information is stored in the table. Using the mv-expand will allow an object to be expanded into a JSON object, which will allow the fields to be referenced. However, mv-expand returns the fields as dynamic. This requires all fields to be casted in the assignments if the target table uses strong typing for the fields.
Following the steps outlined above the views for the different resource types can be created.